

Видео “мебельный степлер”: как пользоваться, как зарядить, и какие нужны скобы
YouTube: пожалуйста укажите корректную ссылку
Для забивания скоб на нужном расстоянии, лучше всего наметить такие места заранее с помощью ручки или карандаша. Также можно воспользоваться фиксатором, который должен соблюдать одинаковое расстояние при вбивании крепежа без наличия предварительной разметки.
Не забываете так же придерживать материал, делая выстрелы, для того чтобы материал не смог съехать при вбивании скобы. Не забывайте так же следить за наличием скоб, чтобы не остаться без них в самый неподходящий для вас момент.
Когда инструмент не используется, фиксируйте рукоять предохранителем. Так положено по технике безопасности. При выполнении этих простых рекомендаций, вы легко справитесь с обвивкой дивана или другой необходимой задачей, связанной со степлером мебельным, цена всегда зависит от вида инструмента и его производителя.
Мебельные скобы
Мы немного затронули эту тему, и стоит её развить
Дело в том, что это хоть и другое направление, но важное для жизни человека, поскольку мебель создаёт интерьер, комфорт, стиль помещения
- Но некоторый строительный монтажный привкус тоже имеется, поскольку, часто, необходимо прибить заднюю стенку шкафа из оргалита либо фанеры.
- В этом случае можно воспользоваться не гвоздями, а степлером со стальной скобой. Это очень быстро и надёжно.
- В процессе производства мебели, часто, применяется оцинкованная скоба.
- Особенно это касается дешёвых изделий из ДСП. В такую основу легко входит практически любая скоба с длинной ножкой.
Чтобы самостоятельно выполнить обшивку мягкой мебели либо отремонтировать стул выгодно опираться на широкую скобу и заострённые ножки. Такая скрепка из нержавейки либо меди не сможет порвать материал, но обеспечит надёжное крепление даже с учётом работы с дубом.
Технические характеристики механических степлеров
Зная устройство и принцип работы строительных степлеров механического типа, необходимо также разобраться с их основными конструктивными характеристиками. К таковым характеристикам принадлежат:
- Материал — из чего изготавливается корпус степлера. Чаще всего используется сталь, а более дешевые варианты производятся из сплава алюминия. Самыми простыми являются изделия из ударопрочного пластика, но они не предназначены для частого и продолжительного применения. Рукоятка стальных и алюминиевых степлеров может покрываться резиновым или полиуретановым слоем
- Размеры и вес — все механические степлеры имеют компактные компактные, поэтому никаких трудностей с их хранением и транспортировкой не возникает. Длина приборов составляет от 155 мм до 230 мм, а высота при этом варьируется от 120 до 200 мм. Ширина 25-35 мм не только характеризует габариты инструмента, но еще и возможность применения скоб разных размеров. Весят ручные модели от 300 до 800 грамм, а если корпус прибора пластиковый, то их масса еще меньше
- Сила удара — этот параметр у ручных скобозабивателей является самым низким, по сравнению с электрическими, и тем более, пневматическими. Сила удара регулируется специальным винтом, которым оснащаются все модели степлеров
- Частота ударов или скорострельность — этот параметр измеряется в количестве забивания скоб за одну минуту. У ручных инструментов этот показатель является самым низким. Электрические модели показывают такие результаты — от 20 до 50 скоб в минуту, а самыми высокопроизводительными являются пневматические аналоги, которые выстреливают 50-60 раз за минуту
- Глубина заколачивания скоб — это параметр зависит от силы удара, которой обладает инструмент, а также типа материала для заколачивания скобы. Механические степлеры способны забивать 10-15 мм скобы, в то время как их современные соперники электрические и пневматические устройства справляются с 50 и даже 100 мм крепежами. Однако в хозяйстве редко возникает необходимость соединения различных деталей при помощи таких длинных скоб, тем более, что намного надежнее выполнить соединение посредством саморезов

Надо отметить тот факт, что ручные степлеры предназначены для забивания скоб в твердые поверхности. Зачастую это древесина, фанера и пластик. Необходимость применения скобозабивателя возникает в случае потребности присоединения тканных материалов к твердым основаниям. Кроме того, что степлер справляется с этой задачей быстро, так еще и получаемый результат отличается декоративностью, именно поэтому эти инструменты получили широкое применение в сфере мебелестроения и ремонта.
В отличие от механических приборов, электрические и особенно пневматические, позволяют прикреплять мягкие материалы к твердым, и даже обеспечивать соединение двух твердых поверхностей. Для таких целей применяются соответствующей толщины и прочности скобы. О том, какие виды скоб для строительных степлеров выпускаются, узнаем далее.
Виды строительного степлера
Существует несколько классификаций строительного степлера в зависимости от ряда параметров. По типу использования выделяют:
- Бытовой отличается пластиковым корпусом и малой мощностью. Его использование ограничено эпизодическим применением в быту.
- Полупрофессиональный большой степлер можно отличить по более качественному корпусу из металла и расширенному функционалу. Такие устройства покупают для проведения ремонта и мелких строительных работ.
- Профессиональный агрегат с металлическим корпусом, высокой мощностью и большим выбором настроек используют мастера ремонта, мебельщики и другие специалисты.
Еще одной общепризнанной классификацией является деление по движущей силе:
- Механический – самый простой вариант, аналог канцелярского.
- Электрический имеет схожее с предыдущим строение, однако для работы нужно применять не физическую силу, а использовать электричество. Бывает степлер строительный аккумуляторный и работающий от сети.
- Пневматический девайс в качестве движущей силы использует давление сжатого воздуха.
Пневматический строительный степлер
Самым мощным и производительным считается пневматический степлер, работающий от подключенного компрессора:
- Скобы подаются при помощи давления сжатого воздуха.
- Такой девайс имеет существенные габариты из-за подключенного компрессора, поэтому используется в основном на мебельном производстве.
- Средняя производительность составляет 50-60 скоб или гвоздей в минуту, что существенно опережает механические и электрические аналоги.
- Прибор может работать с самым большим диапазоном крепежных инструментов и их длиной до 10 см.

Механический строительный степлер
Когда нужна небольшая производительность, можно приобрести простой механический степлер, который работает при помощи физической силы рук. Нажимая на специальную рукоять, пользователь сжимает пружину, которая может быть витого или рессорного типа. Расправляясь, она передает усилие на скобу, выстреливающую из наконечника. Строительный механический степлер обладает следующими преимуществами:




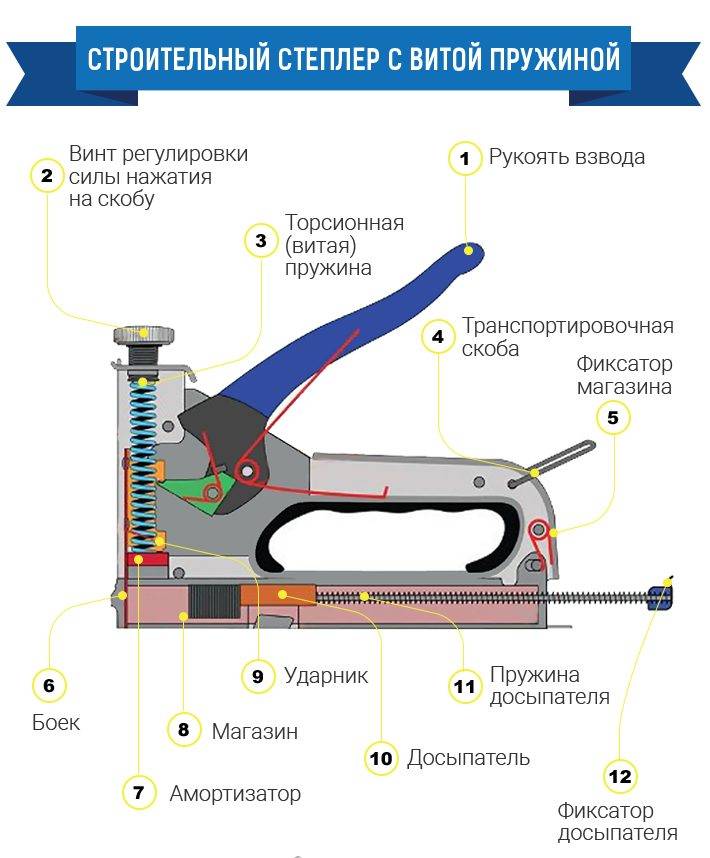

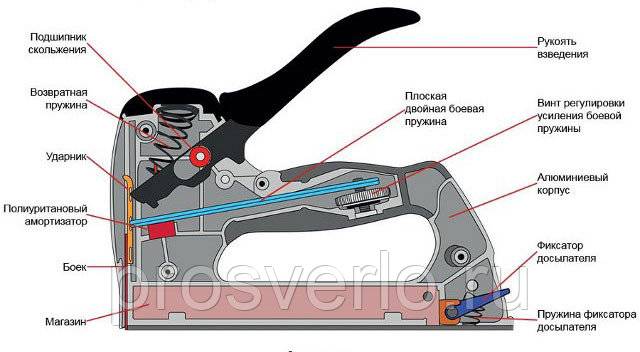


- малый вес;
- небольшие габариты;
- низкая цена.
К основным недостаткам можно отнести:
- необходимость прилагать физические усилия, что утомляет при больших объемах работ;
- низкая производительность не более 20-30 скоб в минуту;
- малое количество элементов, которые помещаются в магазин.

Электрический строительный степлер
Аналогом механического прибора является электрический степлер, в котором энергия пружине подается с помощью электрического тока. Таким образом пользователю не нужно прилагать усилия для работы. Такие приборы бывают двух видов:
- Аккумуляторные . Они удобны отсутствие шнура и возможностью работы там, где нет электросетей.
- Сетевые , которые подключаются к стандартной сети электропитания в 220 В.
Преимуществами такого типа приборов являются:
- высокая производительность до 50 скоб в минуту;
- отсутствие необходимости прилагать физические усилия;
- большой диапазон используемых крепежных элементов;
- разнообразные рабочие настройки.
К недостаткам можно отнести:
- Громоздкость. Аккумуляторные модели весят в среднем 1,5-2 кг, что неудобно при длительном использовании. В сетевых приборах может мешать шнур электропитания.
- Необходимость наличия сети электропитания для работы или подзарядки аккумулятора.
- Высокую стоимость и затраты на оплату коммунальных счетов. Средний строительный электрический степлер потребляет порядка 1,5 кВт в час.

Виды степлеров
Существует множество разновидностей и модификаций скобозабивателей для мебели – их можно разделить на 3 группы в зависимости от конструктивной сложности и производительности.
Самый простой и мобильный вид инструмента, который не нуждается в дополнительных аксессуарах и приспособлениях. Для выполнения операции необходимо лишь приложить физическую силу. Простота конструкции и отсутствие быстроизнашиваемых элементов – залог надежности и долговечности такого устройства. Уход заключается в периодической смазке деталей. Срок службы ручного инструмента – 6-8 лет.
Механический мебельный степлер подойдет для выполнения простых бытовых операций. Для больших объемов работ использовать физическую силу утомительно, а добиться высокой производительности труда невозможно.
Прибор предназначен для выполнения работ среднего объема на профессиональном уровне. Инструмент требуют подключения к электросети. Существуют модификации, работающие на перезаряжаемом аккумуляторе. Ударный механизм приводится в движении нажатием кнопки, физические усилия прикладывать не нужно.
Электрический двигатель увеличивает силу удара в несколько раз. Это позволяет быстро и легко пробивать твердые материалы, а крепление имеет повышенную прочность. Один из подвидов электрического инструмента – строительный степлер, предназначенный для крепления досок, вагонки, плинтусов и других отделочных материалов.
Недостатки электрического прибора – относительно высокая стоимость, повышенная масса за счет двигателя и ограниченная длиной шнура рабочая зона.
Самые производительные, мощные и долговечные модели. Для работы таких инструментов необходим компрессор, поэтому они используются на мебельных предприятиях, где можно оборудовать индивидуальные рабочие места с подачей сжатого воздуха и выделенной электролинией. Для дома и бытовых потребностей их применение нецелесообразно.
Вместо пружины инструмент снабжен пневмоцилиндром. Его приводит в движение воздух, поступающий при нажатии педали или курка. Такое конструктивное решение позволяет во много раз увеличить рабочую силу и выполнять большие объемы работ. Средняя скорость таких пистолетов – 1 скоба в секунду.
В остальном конструкция пневматических моделей достаточно простая и не требует сложного обслуживания. Нужно лишь периодически проводить чистку и по мере износа менять уплотнительное кольцо. Основной недостаток – стационарность. Радиус действия прибора ограничен длиной шланга, подающего воздух.




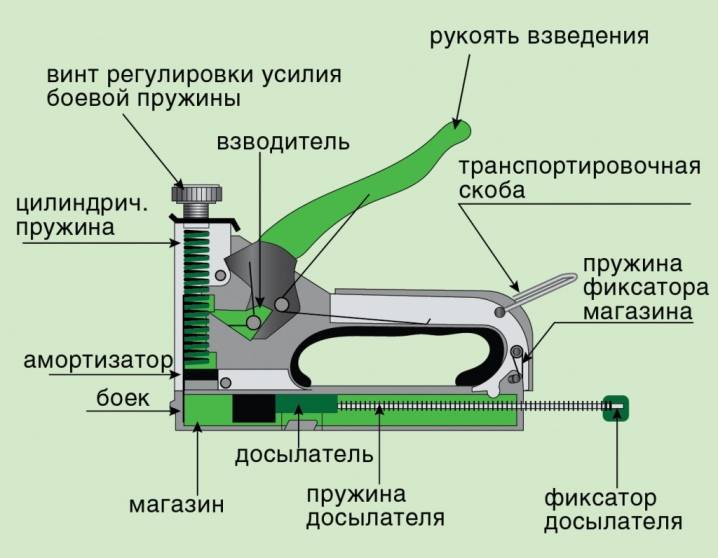

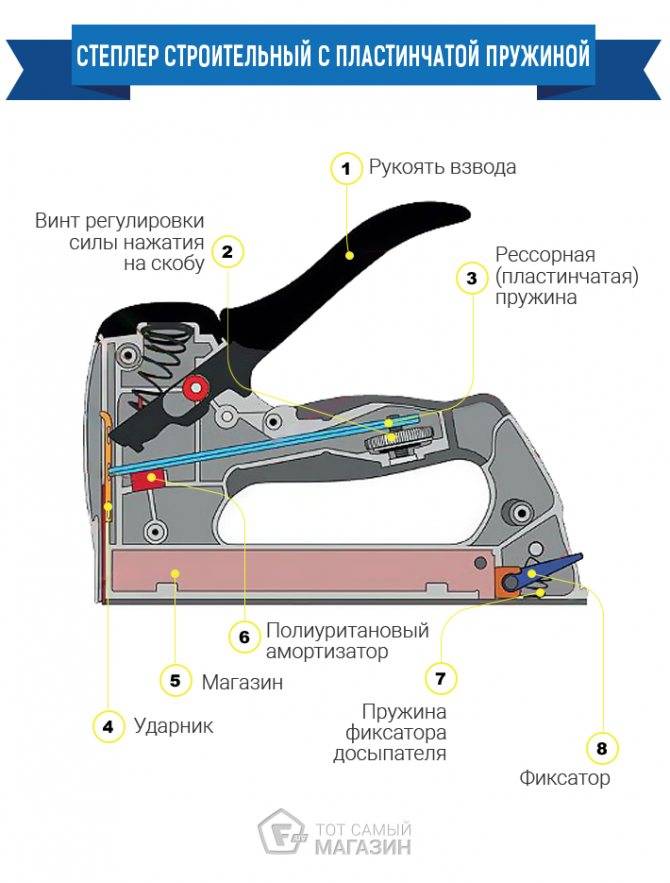



Строительный степлер

Как заряжать степлер? Вначале нужно убедиться, что степлер заблокирован. Затем необходимо найти кнопку, которая открывает лоток. Обычно она располагается на задней стороне устройства. Как заряжать степлер? Из устройства извлекают держатель для скоб. Оставшиеся скобы выбрасывают. Степлер очищают от пыли и мусора. Затем его переворачивают и вставляют в него скобы вверх ногами.
Мебельный степлер является достаточно универсальным инструментом, с помощью которого можно не только выполнить процедуру по обивке мебели, но и ряд других строительных операций.
На сегодняшний день существует несколько видов подобного оборудования, отличающегося между собой по принципу работы:
Пневматический степлер используют в промышленности, а электрический и ручной — в быту. Модели, относящиеся к последнему типу, являются наиболее распространёнными в мебельной промышленности в виду своей мобильности и простоты эксплуатации. Давайте именно на таком примере рассмотрим принцип работы, эксплуатации и ремонта мебельных степлеров.
Однако перед тем, как перейти к данной процедуре, хотелось бы сказать несколько слов о скобах и их разновидностях.
Обзор популярных моделей в разных категориях
Строительные степлеры выпускаются известными фирмами производителями строительного инструмента, например:
- EINHELL;
- SPARKY;
- Bosch;
- METABO;
- STURM;
- NOVUS;
- Intertool.
Рейтинг продукции этих марок многие годы очень высок. Среди стран-производителей наиболее качественные скобозабивные пистолеты выпускают в Германии и Японии. Когда просят «посоветуйте, какой степлер выбрать для бытового или профессионального применения», можно с уверенность указывать на продукцию приведенных фирм соответствующей категории.
STURM ET4516
Модель по отзывам покупателей в 2017 году занимает первое место рейтинга по популярности среди бюджетных вариантов. Как и вся продукция от STURM, инструмент отличается качественной сборкой, а также комплектующими деталями. Движущей силой выступает энергия электрического тока. Подключается модель к стационарной сети напряжением 220 V. Этот электроинструмент работает со скобами и гвоздями, но небольших размеров (6-10 мм и 8-14 мм соответственно). Для бытового применения STURM ET4516 – это хороший вариант.
- низкая цена (около 1200 рублей);
- возможность применения разных типов крепежных элементов;
- качественность сборки;
- простота обслуживания и эксплуатации;
- достаточная скорострельность (20 выстрелов в течение минуты).
- можно применять только небольших размеров скобы с гвоздями, что значительно ограничивает область использования инструмента;
- некоторые неудобства связаны с наличием питающего шнура, ограничивающего свободу действий;
- для работы вдали от питающей сети нужен удлинитель;
- больший вес по сравнению с аналогичными устройствами (1,25 кг).
Bosch PTK 3,6 Li (0603968120)
Bosch PTK 3,6 Li (0603968120) – этот скобозабивной пистолет германского производства, относится к аккумуляторным моделям. Высокое качество обеспечивает надежность, долговечность инструмента. Модель может работать только со скобами размером 11.4х(4-10) мм. У степлера Bosch PTK 3,6 Li (0603968120) высокая скорострельность, что позволяет при его применении повысить эффективность труда. Модификация оснащена аккумулятором на 3,6 V емкостью 1.3 А*ч. По уровню безопасности инструмент превосходит сетевые аналоги.
- высокая скорострельность (30 выстрелов в минуту);
- качество и надежность (гарантия 2 года);
- зарядное устройство в комплекте;
- легкий вес (0,8 кг);
- наличие магазина (на 100 штук скоб);
- можно работать во влажных условиях, а также во взрывоопасных;
- достаточно емкий аккумулятор.
- можно применять только маленькие скобы;
- нужно следить за зарядкой аккумулятора, своевременно подзаряжая его;
- цена превышает стоимость электрических сетевых аналогов (около 4000 рублей).
Intertool RT-0104
Среди механических моделей у потребителей популярностью пользуется Intertool RT-0104. Степлер с кассетным магазином отличается надежной, простой конструкцией. Он является универсальным, позволяющим использовать шпильки (штифты), гвозди, скобы (максимальной шириной 11,3 мм) длиной соответственно: 8-16мм, 8-16 мм, 6-14 мм. Его можно применять во время бытовых строительно-ремонтных работ, а также при сборке мебели. Металлический корпус способствует прочности, долговечности механизма. Наличие резиновых накладок на ручке повышает удобство эксплуатации Intertool RT-0104.
- небольшая масса (0,88 кг);
- функция регулировки силы удара;
- простота эксплуатации и обслуживания;
- несложная конструкция;
- возможность применения разных крепежных элементов;
- низкая цена (около 750 рублей).
- небольшие размеры крепежей, из-за чего ограничивается область использования устройства;
- работа со степлером требует больших затрат времени, сил по сравнению с применением электрических и пневматических моделей.
Чтобы приобретенный степлер, например, для мебели, прослужил долго, необходимо использовать расходные материалы фирменного производства. Нужно регулярно очищать от загрязнений эксплуатируемое устройство, а механические модели смазывать. При выборе изделий главным образом требуется отталкиваться от области их будущего применения. Для быта подойдут механические или электрические модификации скобозабивных пистолетов. Профессиональные устройства можно приобрести, когда предстоит выполнение больших объемов работ, особенно по твердому материалу.
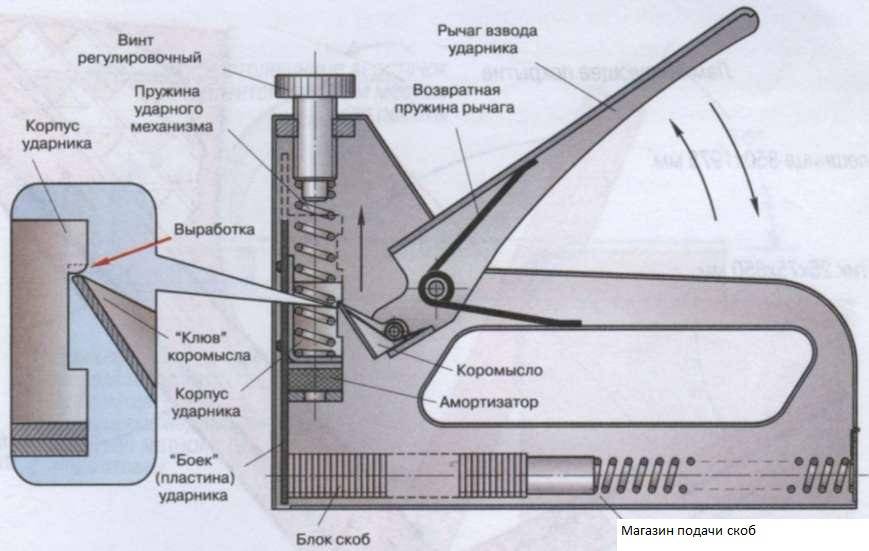
Как отрегулировать степлер?
Регулировка скобозабивающего устройства требуется в случае начала эксплуатации нового инструмента, по мере износа пружины ударного механизма, при переходе на работу с более твёрдым материалом.
Настраивается степлер путём вращения ручки находящейся на верхней части инструмента. Поворачивая его по часовой стрелке, сила удара возрастает, а в обратную сторону ослабевает. По мере износа ударной пружины даже для пробития мягких поверхностей ручку потребуется максимально закручивать. В конце концов, удара не будет хватать для нормального внедрения в поверхности и потребуется покупка нового приспособления.






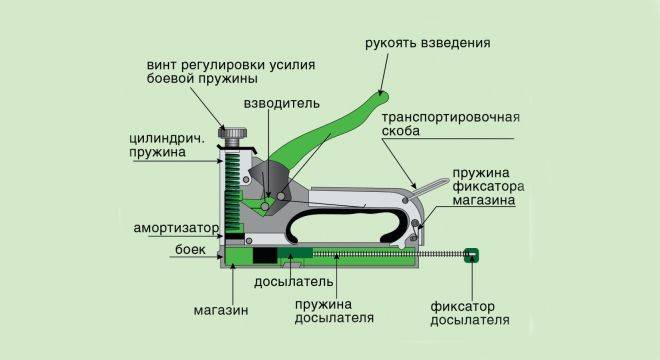
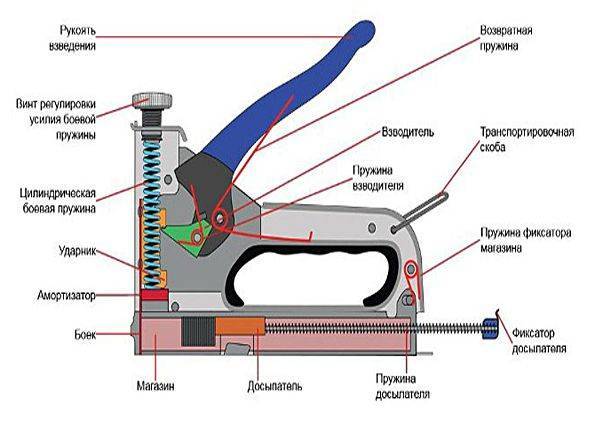
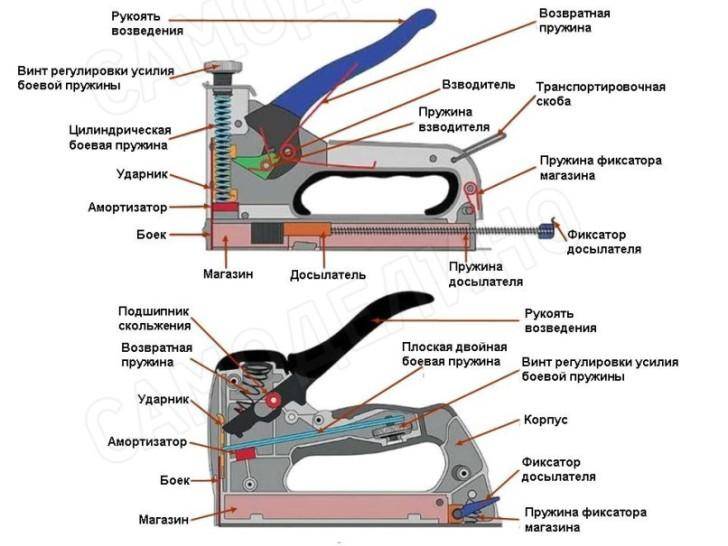

Для продления срока службы пружины, рекомендуется закручивать ручку ровно на столько, насколько это будет требоваться для отдельно взятого материала. Таким образом, пружина не будет лишний раз пережиматься и прослужит ощутимо дольше.
Следует также обращать внимание на габариты скоб
Важно убедиться, что ножки скоб не превышают максимальный предел допустимый степлером. В противном случае скобы не будут полностью входить в скрепляемые детали даже при максимальном сжатии пружины
В противном случае скобы не будут полностью входить в скрепляемые детали даже при максимальном сжатии пружины.
Основные правила работы со строительным степлером
Строительный степлер — незаменимая вещь при необходимости соединения нескольких материалов между собой. Однако при этом необходимо знать, как правильно им пользоваться.
В-первую очередь, необходимо зафиксировать скрепляемые элементы и плотно приставить инструмент к тому месту, где требуется вбить скобу. Затем, не отводя степлер от поверхности материала, необходимо нажать кнопку или пусковой рычаг. Если все будет сделано правильно, то раздастся характерный щелчок, указывающий на то, что скоба зафиксировала материалы между собой.
Кроме того, необходимо не забывать о соблюдении всех правил техники безопасности. Строительный степлер является потенциально опасным инструментом, поэтому при пользовании им необходимо соблюдать следующие условия.
- Запрещено направлять степлер в сторону людей, животных или прижимать их к собственному телу. Иногда скоба может выстрелить самопроизвольно.
- Не рекомендуется пользоваться инструментом при плохом самочувствии или в состоянии алкогольного опьянения.
- Необходимо заранее подготовить рабочее место. Оно должно быть чистым, достаточно освещенным. Следует убрать все посторонние предметы, которые могут помешать проведению работ. Также не стоит забывать о пользовании средствами индивидуальной защиты. Необходимо иметь защитные очки, перчатки.
- Если степлер электрический, то перед его включением в сеть необходимо убедиться в том, что прибор выключен, а на рукоятке присутствует предохранитель.
- Электрическим степлером с поврежденным кабелем пользоваться запрещено. Кроме того, нельзя им работать во влажном помещении или на открытом воздухе во время дождя.
При работе следует защищать глаза очками
Как восстановил мебельный степлер. 4 фишки. Мастер-Ок

Приветствую вас, гости и постоянные читатели! Сегодня вы в гостях у ремонта.
Фото 1.
Приятно, когда инструмент работает безотказно и совсем наоборот, когда много времени уходит на его «оживление! Вот поэтому взялся за барахлящий степлер с целью хоть что-то улучшить.
Разбираю степлер, но не весь
Так как есть неустраняемая проблема с ударом, пришлось залезть внутрь строительного (мебельного) степлера. Для этого:
- Сверху выкрутил регулировочный винт (отвечает за силу удара).
- Снял фиксаторы с верхней и нижнейшпилек и вытащил их.
- Вытащил пружину из блока подачи скоб.
- Изнутри достал ударную пружину с гайкой исамударный механизм.
- Снял с торца крышку корпуса.
Разложил всё и получилось то, что видно на снимке 2. Больше ничего разбирать не стал.

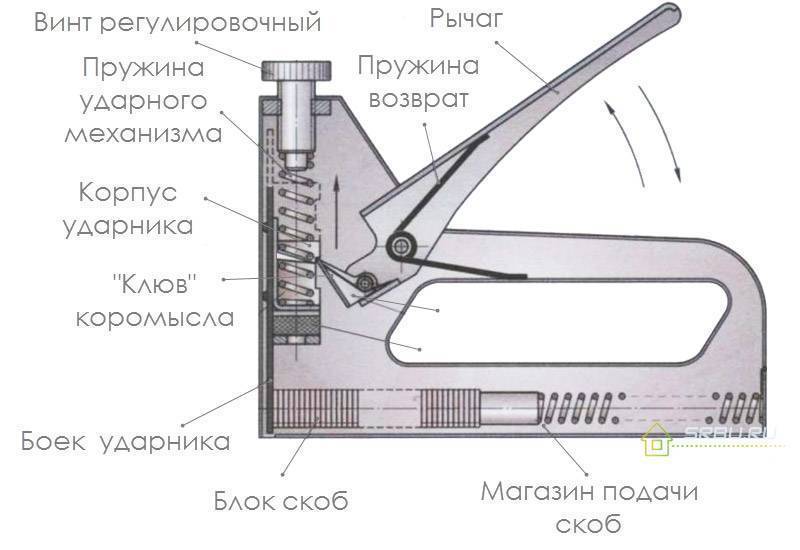


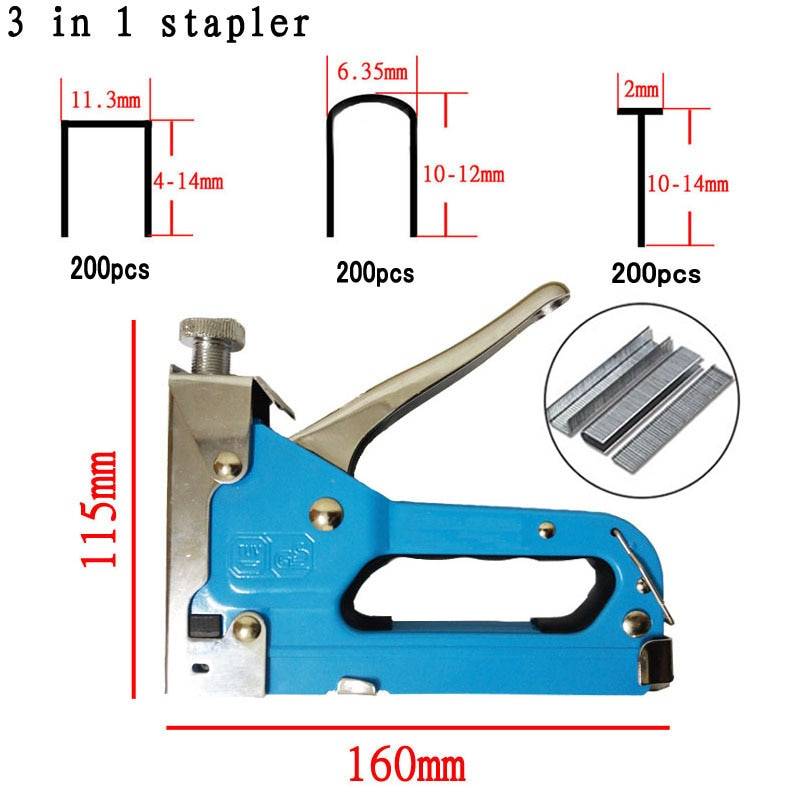





Фото 2. Последовательность разборки может быть иной.
Улучшения
1
.Чистка амортизатора. В разобранном виде с торца видно амортизатор в виде резиновой прокладки, в которую запрессовало много согнутых скоб. На снимке лишь четвертая часть из того, что там было, остальное влетело и выковырял, а это для наглядности. Шаг хотя и простой но поможет избавиться от заклинивания из-за попадания скоб в механизм.
Фото 3.
2. Рихтовка крышки корпуса.
Так как иногда боёк выстреливал по две скобы вместе, решил немного молотком подогнуть верхнюю крышку корпуса в месте выхода скоб. Получилось немного уменьшить зазор и теперь две точно не выскочат
Важно не перестучать, а то и боёк не пройдет потом
Фото 4а,б. На «а» виден небольшой изгиб крышки, который выпрямил молоток.
3. Устранение выработки в корпусе ударника.
Выработка была небольшой, поэтому подравнять угол до 90 градусов получилось достаточно быстро. В этом помог крупный напильник.
Из-за большой выработки степлер выстреливает раньше времени, так как зацеп или клюв, что на рукоятке, просто соскальзывает при нажатии.
В остальном ударный блок вроде бы вопросов не вызывает.
Фото 5.
4. Установка гроверов.
Нашел парочку гроверных шайб и одел их на утонченный носик регулировочного винта. Это могли быть и шайбы такого же диаметра. Данный ход обусловлен тем, что пружина со временем ослабевает и при ударе сжимается/разжимается уже не с такой силой. За счет подкладки граверов её можно поджать еще на 4-5 мм, она становится жестче и боек лучше забивает скобы. Но такой номер проходит не на всех моделях, так как есть конструктивная разница.
Фото 6.
После сборки прошли испытательные «стрельбы» в жесткую десятислойную фанеру. Скобу на 12 мм, конечно не загнал всю, а вот 5 и 6 мм утопил полностью, а это то, что надо. И порадовало, что по две скобы уже не вылетают. В сравнении с тем, что было, улучшения налицо!










Если вы одобряете материал, ставьте лайк. А ещё подписывайтесь
на канал, чтобы не пропустить что-то новое и необычное!
Несколько советов по выбору степлера
Степлер мебельный, инструкция по применению: как выбрать скобы?
В инструкции к прибору есть данные, на которые вы должны опираться в выборе скоб:
- Глубина скоб – она может варьироваться от 4 до 14 мм. Этот параметр определяется характером предстоящих работ. Например, гобелен на спинку кресла можно “пристрелить” скобами 8 мм, а для войлока уже понадобится использование глубины в 10 – 12 мм.
- Тип – тут все зависит от модели, маркировка на упаковке должна быть той же, что и в описании к прибору. Например, если скобы малы для конкретного прибора, то они могут “выстреливаться” по нескольку штук за один раз. Кроме того, тут почти неизбежен перекос скоб в лотке.
Кроме того, следует с осторожностью относиться к рекомендациям продавца заменить скобы одного типа другим, похожим. Заряды, схожие по глубине, могут отличаться геометрией, что может быть незаметно на глаз, но критично в работе степлера

Как правильно выбрать мебельный степлер?
Вы задумались, как выбрать степлер для мебели? Тут все очень просто: выбор осуществляем исходя из того, какого рода работы нам предстоят. Так, если вам нужно устройство для обивки дивана или кресла, то можно обойтись механическим прибором, потому что каркасы мебели изготавливаются, как правило, из мягкой древесины. Усилия, предаваемого рукой механическому степлеру, для работы будет вполне достаточно.





